
こんにちは、tayoの土井です。
先日(2025年10月)、弊社では、登録いただいたプロフィールの内容をもとに、AIを用いたスキルベースの適職診断を受けられる機能をリリースしました。
私は裏側でデータサイエンスを担当し、スコアリングロジックの設計・検証などを行いました。AIシステムによって、これまで出会えなかったキャリアの可能性を提示できることは素晴らしいと考えています。一方で、AIが人のキャリアや能力評価に関わる以上、公平性やバイアスの観点から、慎重に向き合う必要があるとも感じています。
私自身、進学先の米国メディカルスクールで、臨床試験の参加者が特定の性別や人種に偏ることで、医療データそのものが公平性を欠くことを学びました。昨今急速に普及している生成AIでも同様の問題が懸念されています (例:Bloomberg の生成 AI/バイアス特集)。今回のスキル評価AIでも、同じような構造的課題が潜んでいるのではないか——そんな問題意識が、この検証の出発点になりました。
今回の記事では、スキル評価AIでどのようなバイアスが生じうるのかを、社内での実験的な検証を通して紹介します。網羅的な調査ではありませんが、AIの公平性(AI fairness)をめぐる対話のきっかけとして、皆さんと一緒に考えていければうれしく思います。
それでは、どうぞ。
Introduction
AIによる人材評価は、人間の主観的判断を軽減しうる手段として注目されている。しかし、AIは訓練データの偏りをそのまま学習してしまい、バイアスを再生産する危険性もある。
実際、Amazonは2014年より履歴書をスコアリングして採用候補を選択するAIシステムを開発したが、最終的には女性を不利に評価する傾向が検出されたため、このプロジェクトを中止したと報じられた(Dastin, 2018, Reuters)。このAIは性別を明示的に入力変数として含めていなかったものの、学習データにおける過去の採用履歴の偏りを学習した結果、「women’s chess club」といった課外活動名や女子大出身など、性別を示唆する語句を含む履歴書を低く評価する傾向を示した。これは、明示的な属性を排除しても、社会的バイアスを再現してしまう例である。
さらに、近年急速に使用が拡大している大規模言語モデル(LLM: Large Language Models)においても、公平性の検証が進められている。OpenAIによる“Evaluating fairness in ChatGPT”レポート(OpenAI, 2024)では、同一のプロンプトに対してユーザー名を性別(男性的な名前、女性的な名前)や人種・民族的背景を示唆する名前に設定し、ChatGPTの応答を比較している。その結果、有害なステレオタイプを反映する応答の割合は全体の約0.1%(古いモデルでは最大1%)と報告されている。このような結果は、名前などの言語的手がかりからAIが社会的文脈を推測し、応答内容に影響を及ぼす可能性を示している(プロキシバイアス)。
もっとも、バイアスのない人間はいないとも言われるように、完全に中立的な判断を行うことは人間にもAIにも難しい。さらに、「バイアスとは何か」という定義自体も一義的ではなく、文化・社会・時代によって変化する。AIの公平性(AI fairness)を検証するための手法や、AI事業者向けのガイドラインは国内外で整備されつつあるが(例: 経済産業省 AI事業者ガイドライン(第1.1版)/ EU AI Act)、実務レベルでどのように検証し、どの程度の差を「許容範囲」とみなすかについては、いまだ統一的な答えは存在しない。
今回使用するモデルにおいても、以下の2点が懸念として挙げられる。
- 評価バイアス(outcome bias):性別によって評価結果に偏りが生じるか。
- プロキシバイアス(proxy bias):性別を明示的に入力しなくても、他の言語的特徴から性別を推測して評価に利用してしまうか。
※バイアスの要素は性別に限られないが、検証の第一歩として明示的かつ比較可能な属性である性別を用いた。
本研究ではまず前者、評価バイアスの有無を検証した。具体的には、同一のプロフィール文に対して、あえて「男性」「女性」といった性別語を明示的に挿入し、それによってスキル評価結果がどの程度変化するかを定量的に比較した。この手法により、性別という明示的な属性が評価に影響を与えるか、を確認することを目的とした。
なお、性別語を挿入しない状態でも、文体や語彙などの特徴からモデルが暗黙的に性別を推測している可能性(プロキシバイアス)は存在し得る。そのため、本研究はその第一段階として、性別情報を明示的に与えた際に評価結果に差が生じるかどうかを検証したものである。
Methods
分析対象: tayoユーザー500名のプロフィール文(充実度の高いものを選定)から、女性50名・男性50名をランダムに抽出。
データ生成: 名前などは抜いたうえで、各プロフィールに性別語「男性」を追加したものと「女性」を追加したものを作成
分析手法: 同一プロフィールの「男性条件(M)」と「女性条件(F)」の結果を1ペアとし、計100ペアを比較した。
指標: 平均差 (M−F)、効果量 (Cohen’s dz)、対応のあるt検定
プロンプトやモデルに関しては企業秘密であるが、可能な範囲で名前などのバイアスとなりうる情報を取り除くような処理を入れている。
Results
1 全体傾向
性別語の挿入によるスキルスコアの差を、「平均差(Mean difference, M−F)」を指標として解析した。ここでの平均差とは、各スキルについて同一人物の男性条件(M)と女性条件(F)のスコア差(M−F)を算出し、その平均値を取ったものである。値が正(+)の場合は男性条件で高く評価され、負(−)の場合は女性条件で高く評価されたことを示す。
その結果、男性条件で高く評価されたスキルは72件(平均差 +0.060)、女性条件で高く評価されたスキルは75件(平均差 −0.053)であった。
全体としては男女間で大きな偏りは見られず、ほぼ拮抗した傾向を示した(図1)。
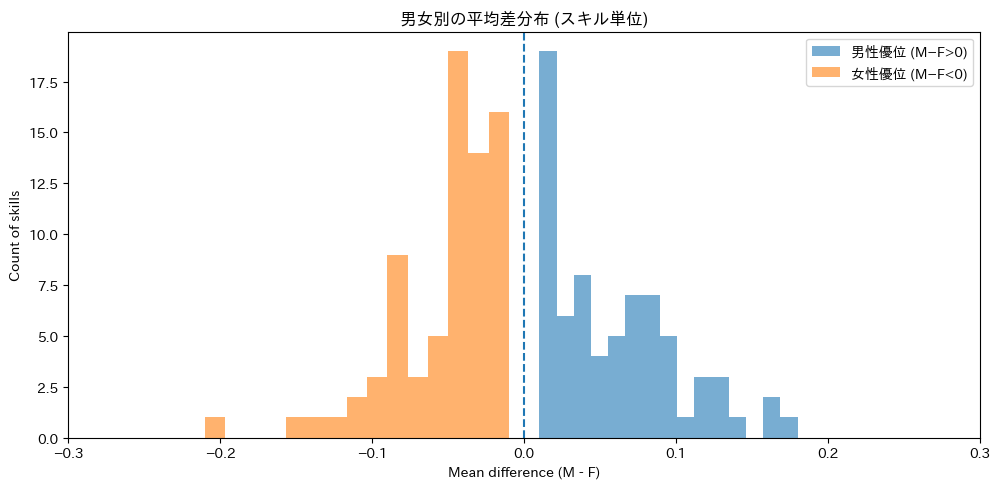
図1: 性別語の挿入によるスキル評価差の分布
2 スキル別の統計的検証
各スキルについて、対応のある t 検定(paired t-test)を実施したところ、154スキル中5スキル(約3%)で有意な差(p < 0.05)が確認された。
これらのスキルにおける効果量(Cohen’s dz)は0.2〜0.3程度であり、小〜中程度の効果に相当した。なお、今回は多重比較補正(Bonferroniなど)は行っていない。
3 有意差が見られたスキルの例
本研究では、各スキルを5点満点で評価として検証した。有意差が見られたスキルの一例として、「クラウドコンピューティング」では差分(MーF)が -1〜+3の範囲に分布し、平均差は +0.5 であった。すなわち、男性条件でやや高く評価される傾向がみられた(図2a)。
一方、「マテリアルインフォマティクス」では差分(MーF)が -2〜+1 の範囲に分布し、平均差は -0.8 程度であり、女性条件でやや高く評価される傾向が確認された(図2b)。
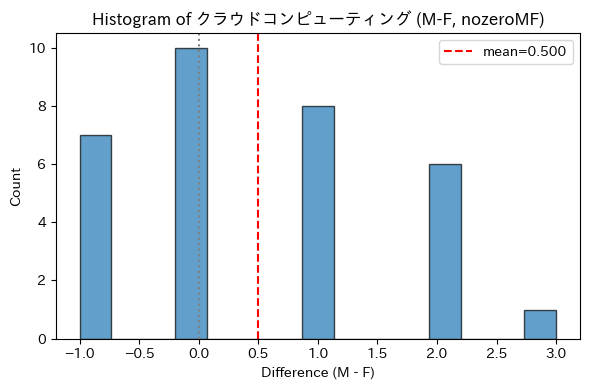
図2a: 「クラウドコンピューティング」スキルにおける性別条件間のスコア差分布
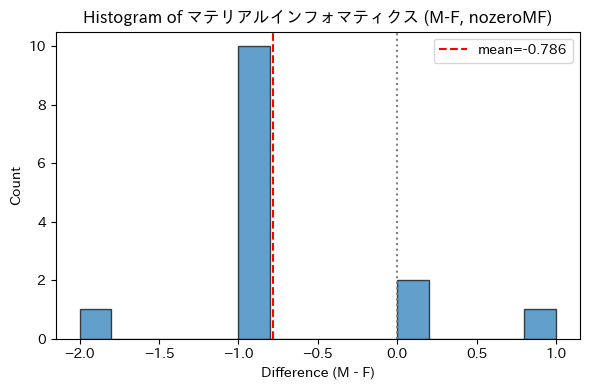
図2b: 「マテリアルインフォマティクス」スキルにおける性別条件間のスコア差分布
※図では男性条件、女性条件どちらも0点の評価だったものは省いた。
4 個人レベルの差異
個人レベルでの比較では、同一人物のプロフィール文に「男性」と「女性」を入れ替えるだけで、一部のスキルにおいて最大値と最小値の差に匹敵するスコア差が確認された。
これは、プロフィール文からスキル評価に至る過程で、特定の研究用語や文脈がどのように抽出・解釈されるかに依存していると考えられる。
中間処理にもAIが利用されており、この差が生成過程の確率的変動(stochasticity)によるものなのか、あるいは性別語の影響によるものなのかは、本研究の範囲では特定できなかった。
Discussion
本研究では、全体として明確な性別バイアスは限定的であったが、一部のスキルの評価において、統計的に有意な差が観察された(p < 0.05)。ただし、多重比較補正を行っていないため、これらの差は探索的な結果として解釈する必要がある。また、個人レベルの比較では、性別語の影響であると断定はできないものの、同一人物のプロフィール文に「男性」と「女性」を入れ替えるだけで、一部のスキルにおいてはスコアの最大値と最小値の範囲に匹敵する差が確認された。この差がモデルの確率的な出力変動(stochasticity)によるものか、あるいは性別語の影響によるものかは、現段階では明らかではない。
本研究では性別語を操作変数として扱ったが、出身地、使用言語、年齢など、他の属性についてもバイアスが生じる可能性がある。また、明示的な属性語がなくても、文体や語調といった言語的特徴からモデルが属性を推測してしまうリスクもあり、この点についても今後の検証が求められる。
また、性別などの属性に関するセンシティブ情報の扱いについては、単に「入力しない」ことで偏りを防げるわけではない。むしろ、それらをどのように扱い、モニタリングしていくかを社会的に合意していく必要がある。センシティブ情報の利用は、プライバシー保護や差別防止の観点と表裏一体の課題であり、「取る・取らない」という二分法では整理できない。実際、アメリカ・ニューヨーク市では、AIを用いた採用プロセスにおける偏りの監査を義務づける条例(Local Law 144, 2023)が施行されている。
このように、AIの公平性をどのように定義し、検証・監視していくかは、法制度や社会的価値観の変化とともに更新されていく課題である。
さいごに
個人的な感想になりますが、本件を開発チーム内で議論するとき、「AIの公平性」というテーマをどのタイミングで、どのように切り出すか迷いや不安がありました。開発チームの中に多様な視点や背景を持つメンバーがいることの重要性を改めて実感しました。
また、データ抽出のために、充実度の高いtayoユーザー500名のプロフィール文を分析した結果、女性と推定できる方は全体の2割以下でした。この比率は、データの多様性という観点からも課題であり、より多様なユーザーに登録してもらえるようにすることが重要だと感じています。
AIの分野に限らず、歴史的にもデータや研究の設計から女性やマイノリティが排除されてきた経緯があります。多くの領域で、こうした偏りが技術の公正性や安全性に影響してきたことが指摘されており、これを是正し、研究やイノベーションの段階から多様な視点を取り込もうとする考え方は、Gendered Innovation(ジェンダード・イノベーション)と呼ばれています。
多様な視点や背景を持つ人々がモデル設計・データ選定・評価プロセスに関わることで、技術はより公平で信頼性の高いものになっていく。今回の検証をきっかけに、社内外でこうしたテーマを率直に話し合えるきっかけになれば嬉しいです。







東京大学工学部機械情報工学科でロボティクス・機械工学などを学んだ後、ハーバード大学にてマウスの姿勢制御の研究に従事。2023年に博士号(神経科学)を取得、2024年1月よりtayoにジョイン。女性研究者のコミュニティと起業支援WISERの統括と自社プロダクトのデータサイエンスを担う。